The Problem & Solution
Conversational recommender systems are often trained and evaluated using proxy metrics (Recall@K, BLEU) that weakly reflect true user-aligned recommendation quality. HARPO reframes conversational recommendation as a structured decision-making problem, explicitly optimizing for user satisfaction, relevance, diversity, and engagement.
Abstract: Conversational recommender systems (CRSs) operate under incremental preference revelation, requiring systems to make recommendation decisions under uncertainty. While recent approaches, particularly those built on large language models, achieve strong performance on standard proxy metrics such as Recall@K and BLEU, they often fail to deliver high-quality, user-aligned recommendations in practice. This gap arises because existing methods primarily optimize for intermediate objectives like retrieval accuracy, fluent generation, or tool invocation, rather than recommendation quality itself.
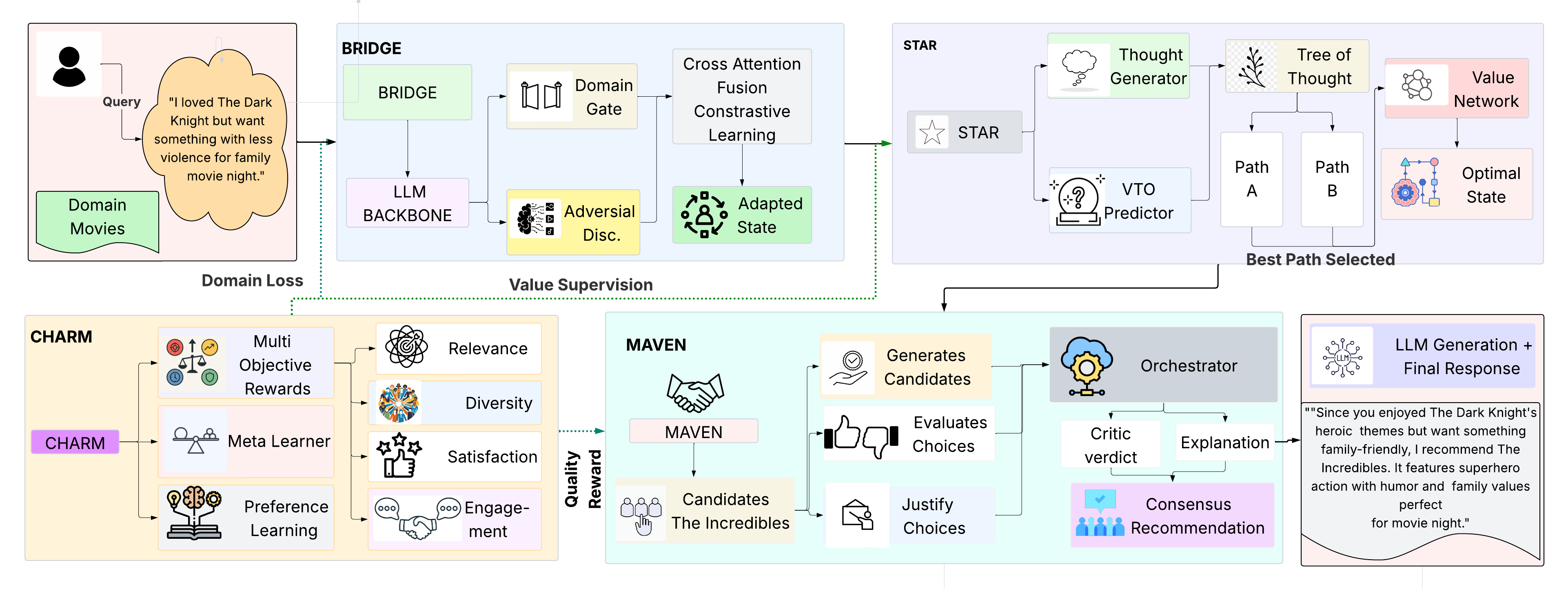
HARPO integrates: (i) CHARM — hierarchical preference learning that decomposes recommendation quality into interpretable dimensions (relevance, diversity, predicted user satisfaction, and engagement) and learns context-dependent weights; (ii) STAR — deliberative tree-search reasoning guided by a learned value network; (iii) BRIDGE — domain-agnostic reasoning abstractions enabling cross-domain transfer; and (iv) MAVEN — multi-agent refinement through collaborative critique.
Framework 4 Components
HARPO integrates four tightly coupled modules built on a shared language model backbone (DeepSeek-R1-Distill-Qwen-7B).
Structured Tree-of-Thought Agentic Reasoning
Beam search over structured reasoning states guided by a learned value network that predicts multi-dimensional recommendation quality rather than task completion.
Contrastive Hierarchical Alignment with Reward Marginalization
Decomposes recommendation quality into four reward dimensions with context-dependent meta-learned weights and margin-based preference optimization.
Cross-Domain Transfer
Adversarial domain adaptation with learnable domain gates — preserves domain-invariant reasoning patterns while retaining domain-specific information.
Multi-Agent Refinement
Three specialized agents (Recommender, Critic, Explainer) collaborate through shared representations with an agreement loss promoting coherent consensus.
Evaluation Metrics User-Aligned
HARPO introduces a quality-centric evaluation perspective separating user-aligned measures from standard proxy metrics.
Leaderboard
HARPO BenchmarkRankings across three datasets on user-aligned metrics. Click any column header to sort. Filter by model type or search by name. Higher is better for all metrics.
| # | Model | Satisfaction ↕ | Engagement ↕ | Div.-Adj. Relevance ↕ | Human Pref. ↕ | Overall Score ↓ |
|---|
† Text-only adaptation. ‡ Fine-tuned per Wang et al. 2025. Scores normalized [0,1]. Human Pref. = Table 8 Overall score (1–5, normalized).
Submit Your System
Paste your results JSON below. Evaluated against the official HARPO benchmark API at github.com/harpo-bench/harpo.
📋 Paste Results JSON
All fields required. Results are verified server-side using the HARPO evaluation API.
View full JSON schema
{
"method_name": string,
"team": string,
"dataset": "redial"|"inspired"|"muse",
"predictions": [{ "conv_id": string, "recommended_items": number[] }],
"paper_url": string | null,
"code_url": string | null,
"description": string // ≤ 200 chars
}